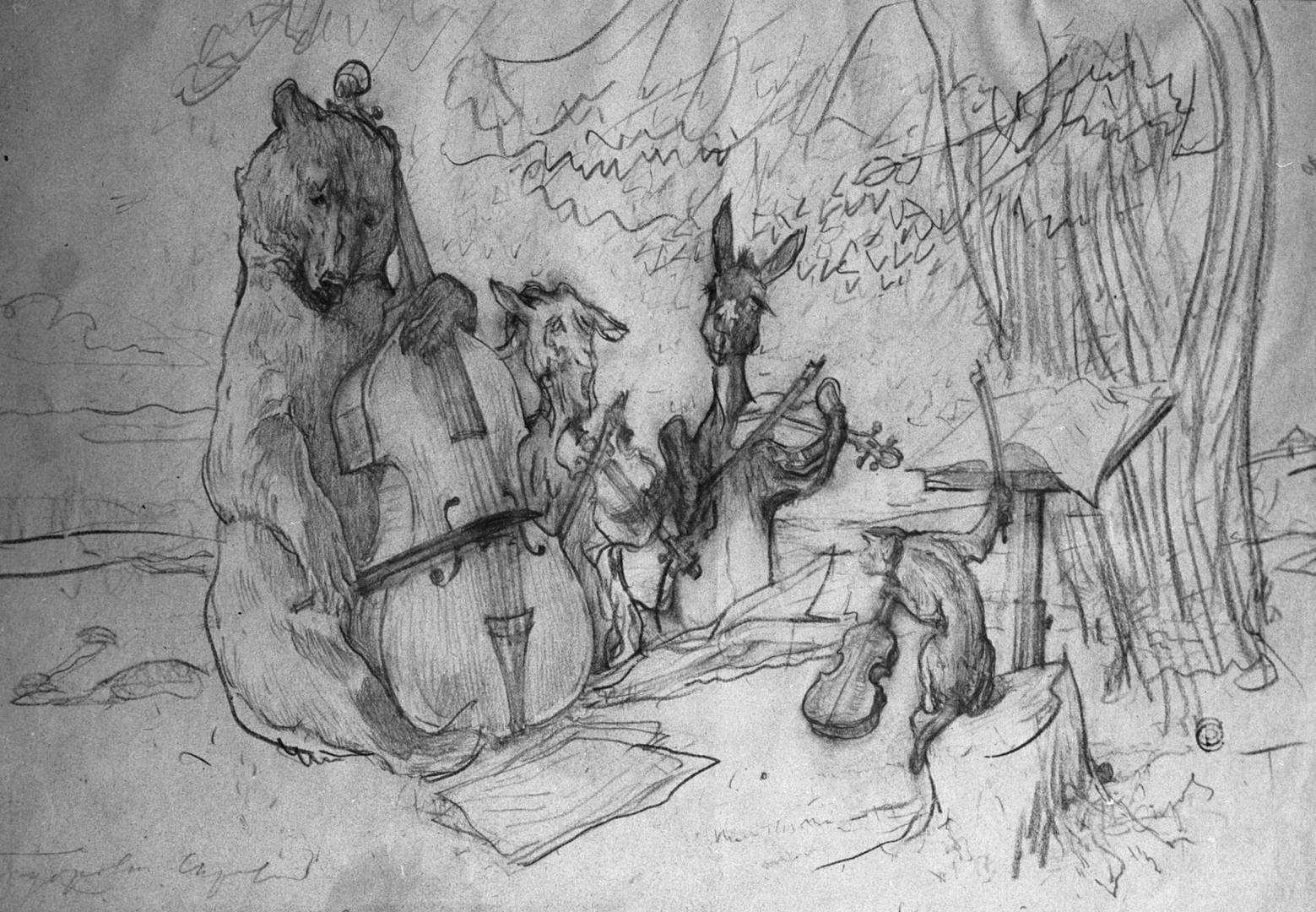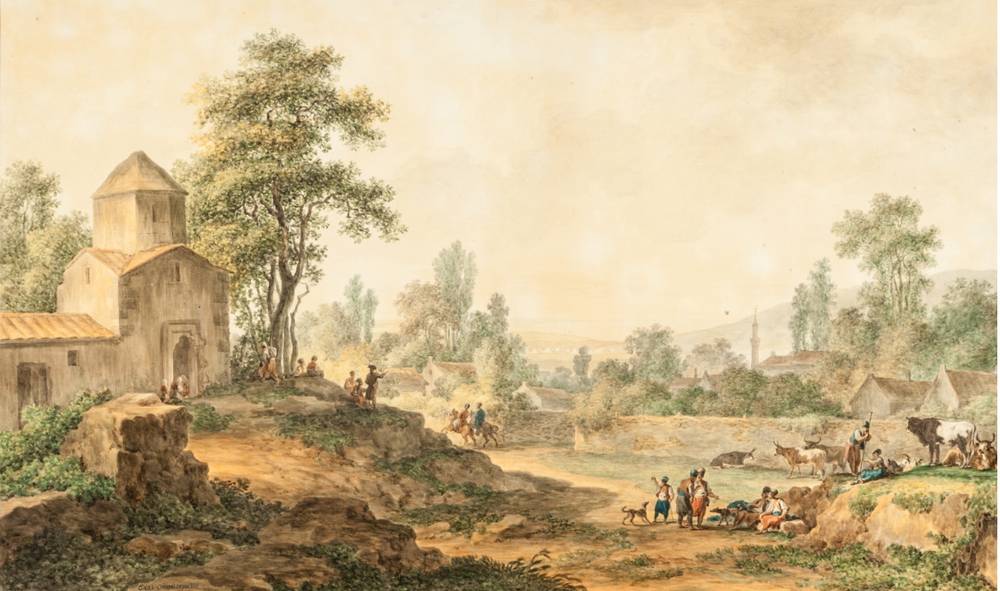Нейросеть научили рисовать в стиле Хаяо Миядзаки
Нейросетевой алгоритм GANILLA для преобразования фотографий в иллюстрации создал коллектив турецких ученых под руководством Самета Хиксонмеза (Samet Hicsonmez), 14 марта сообщает YouTube-канал Two Minute Papers.
Оказалось, что имеющиеся нейросетевые алгоритмы для преобразования стиля изображений (CycleGAN, DualGAN, CartoonGAN) плохо справляются со стилями иллюстраторов. Изображения получаются чересчур гротескными из-за того, что нейросети применяют стиль ко всему изображению без разбора, не разделяя объекты и фон.

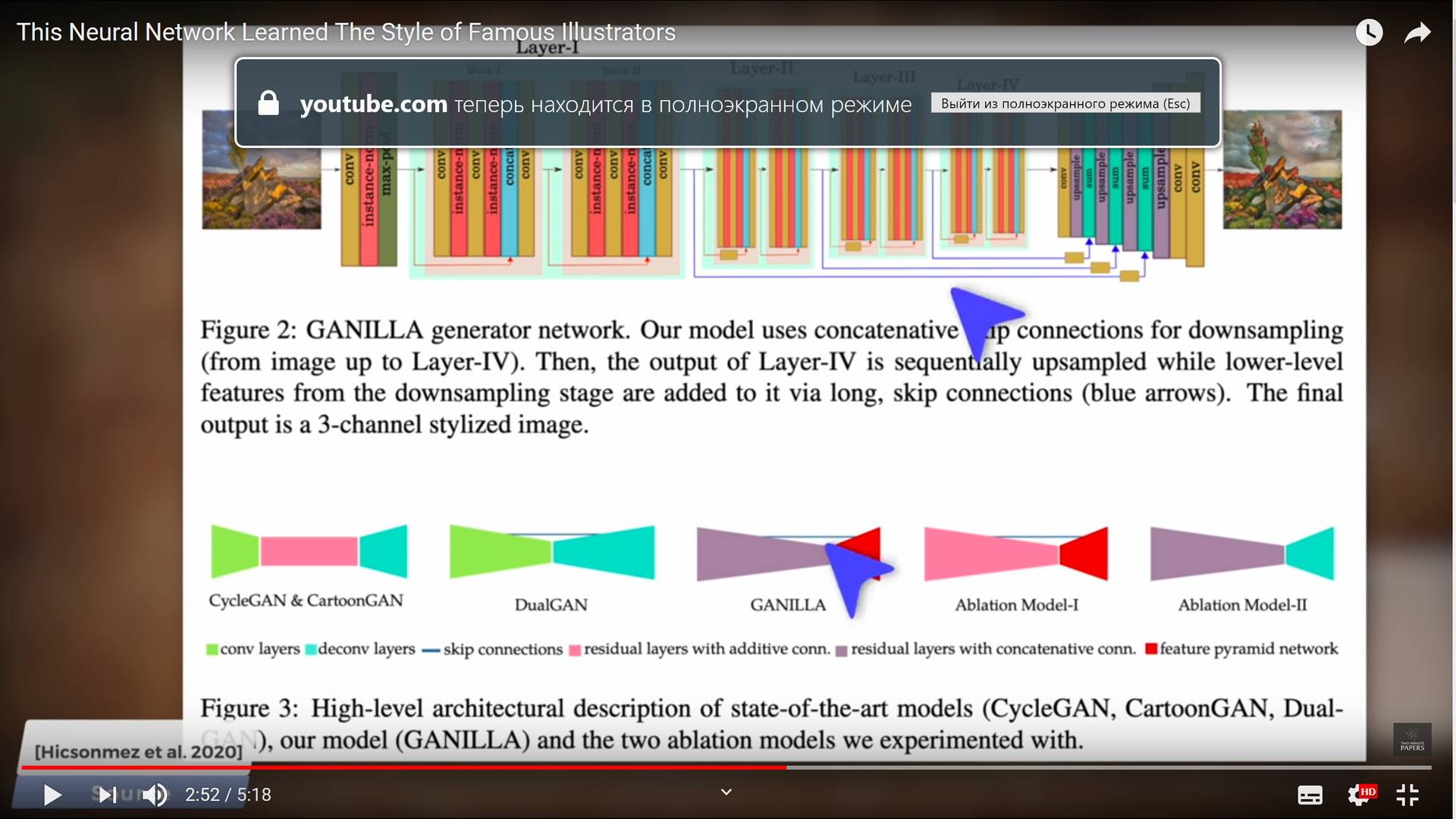
С задачей лучше справляется предложенный авторами алгоритм, названный ими GANILLA (Generative Adversarial Networks for Image to Illustration Translation, генеративно-состязательной нейросетью для преобразования изображений в иллюстрации).
Ключом успеха в данном случае послужило использование при синтезировании изображения дополнительных обходных связей, позволивших эффективно соединить информацию входного изображения с результатами вычислений глубинной нейросети.
Напомним, генеративно-состязательная нейросеть (англ. Generative adversarial network, GAN) — это подход к созданию нейросетей, способных генерировать изображения, похожие на изображения обучающего набора. Такая нейросеть состоит из двух состязующихся сверхточных подсетей, в процессе работы обучающих друг друга.
Первая генерирующая нейросеть пытается синтезировать изображение на основании некоего «понимания» стиля (это может быть стиль художника или особенности портретов стариков либо женщин). Вторая, дискриминирующая нейросеть, пытается отличить синтезированное первой нейросетью изображение от естественного.
Обе нейросети обучаются попеременно на обучающем наборе фотографий и обучают друг друга. Генеративная нейросеть начинает со случайных настроек и синтезирует нечто поначалу маловразумительное. Дальше обучающая выборка и результаты этой еще несовершенной генерации используются для обучения дискриминирующей сети — при обучении добиваются, чтобы нейросеть могла как можно лучше отличить сгенерированное от обучающей выборки.
Далее идет обучение генеративной нейросети — при обучении добиваются, чтобы на вновь сгенерированных примерах ошибалась ранее обученная дискриминирующая нейросеть и принимала бы их за естественные изображения. Далее цикл многократно повторяется, и генеративная нейросеть учится всё лучше синтезировать нечто похожее на обучающую выборку.
Если в качестве обучающей выборки использовать картины пейзажиста с характерным стилем, а генеративную сеть заставлять преобразовывать какие-нибудь реальные пейзажные фотографии, то в результате состязания с дискриминативной нейросетью получится механизм, способный создавать из поданной на вход фотографии имитацию картины данного художника. Аналогично можно научить нейросеть «состаривать» портреты, если обучать на портретах стариков, или преобразовывать мужской портрет в женский, если обучать на портретах женщин.
Читайте также: Китайские ученые создали нейросеть для сглаживания движения на видео