Разработана система различения живого голоса от подделки
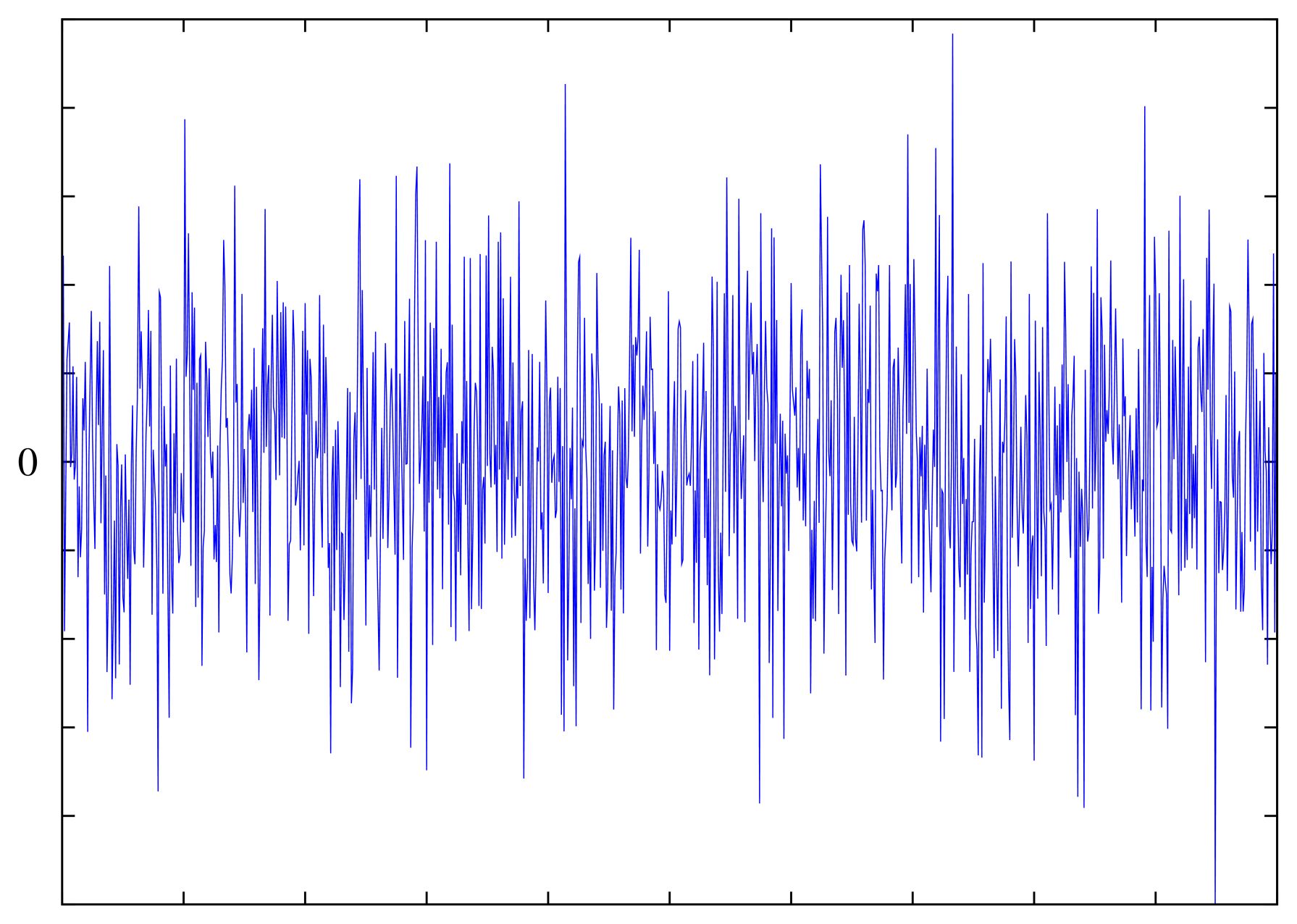
Технология различения живого человеческого голоса от подделок на основе записей и синтеза разработана подразделением Data61 Государственного объединения научных и прикладных исследований Австралии совместно с компанией Samsung и университетом Сонгюнгван, 22 июня сообщает ZDNet.
Информационные атаки или шутки с подменой голоса (голосовым спуфингом) сегодня не редкость. Иногда спуфинг применяется для взлома устройств или учетных записей на сервисах, если проверка пользователи основана на идентификации голоса. Притом отличить голос живого человека от качественной аудиозаписи очень сложно.
Совместная австралийско-корейская разработка Void, как стало известно, позволяет отличить живой голос весьма точно. При этом она построена не на базе технологии машинного обучения, когда искусственной нейронной сети передают большое количестве размеченных примеров, а на анализе спектрограммы.
Технология позволила добиться точности распознавания 99% для той подборки аудиозаписей, которую группа разработчиков исследовала, и 94% на случайной выборке. Программа на базе этой технологии сумела распознать все восемь пробных атак с голосовым спуфингом. И сделала это заметно быстрее, чем аналоги на базе нейронных сетей.
Разработчики обещали представить работу с подробным рассказом о технологии на конференции по безопасности, которая состоится в августе.